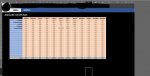
The part that you ask about creates an array of column numbers, <>0 is a logical test of the range returned by index. COLUMN($C$1:$N$1)/(INDEX($C:$N,V4,0)<>0) would generate the array, COLUMN({3,4,5,6,7,8,9,10,11,12,13,14})/({0,0,1,2,0,1,5,0,0,0,0,0}<>0) where the second array (in bold) shows the values in the row specified in V4 of columns C:N.
The <>0 test at the end results in any 0 values equating to FALSE or non 0 values equating to TRUE. Dividing the column numbers by TRUE of FALSE will result in an array containing numbers and errors, from the above example the final result would be {#DIV/0!,#DIV/0!,5,6,#DIV/0!,8,9,#DIV/0!,#DIV/0!,#DIV/0!,#DIV/0!,#DIV/0,!}.
The aggregate function ignores the errors and returns either the lowest, AGGREGATE(15,6,...) or the highest, AGGREGATE(14,6...) column number in the array.
You do need the parts in bold that you said you had to delete though, otherwise the resulting range will be out significantly, the numbers in V5 and V6 are not actual column numbers, they are position references relative to column C.
V5 should be the difference between column C and the first non zero data column, for example if the first value is in column C then V5 should show 0, not 3, as would be shown with the bold part deleted.
V6 should be the number of columns to be included in the range, for example with non zero values in columns C, E and G, the formula will show 5 (C,D,E,F and G), with the bold part removed from this formula it will incorrectly show 7.
Based on the above, the resulting range should be C5:G5 but with the bold parts removed and the column numbers in the cells instead of the corrected positions the actual range returned will be F5:L5 which is missing most of the actual data.

")