I can offer one more simplification that might make the first offering more tolerable. If all group tables are left alone--not appended to each other--then the Traffic code in each Group table will need to be searched for the next matching Traffic code corresponding to the one in the SourceResult table. In this somewhat improved version, two helper tables are constructed somewhere out of the way (they can be hidden also). These helper tables eliminate the tedious cumulative summing of the number of matches that occurred in Group tables examined previously. The first helper table is formed by listing the unique Traffic codes that appear in the final SourceResult table (these are the row headers) and by listing reference names for each of the Groups (these are the column headers). Then the data within this helper table comes from a simple COUNTIF formula whose criteria range is edited to match that of the corresponding Group. The second helper table uses the first one to perform a cumulative sum of matches for all prior Groups to the left of the current one. Then any prior cumulative sum can be readily determined with a simple lookup in this 2nd helper table. In this example, the data in the 2nd helper table are found in $BO$13:$BT$17, the row headers are in $BN$13:$BN$17, and the column headers are in $BO$12:$BT$12. So we can find the prior cumulative sum for any Traffic code in $BA4 and down (the Traffic codes listed in the SourceResult table), for any particular Group (e.g. "Group 1") using this construction:
INDEX($BO$13:$BT$17,MATCH($BA4,$BN$13:$BN$17,0),MATCH("Group 1",$BO$12:$BT$12,0))
Once the appropriate ranges are adjusted to the actual worksheet, the only dynamic parts of this formula are the $BA4 Traffic code reference and the Group name.
So this formula can be substituted into what was offered previously, leaving us with a Group 1 formula component that looks like this:
IFERROR( INDEX(
$R$4:$U$27, AGGREGATE(15,6,
(ROW($U$4:$U$27) - ROW($U$4)+1) / (
$U$4:$U$27=$BA4),
COUNTIF($BA$3:$BA3,$BA4) -
INDEX($BO$13:$BT$17,MATCH($BA4,$BN$13:$BN$17,0),MATCH("Group 1",$BO$12:$BT$12,0)) + 1), COLUMNS($BC:BC) ),
Studying this closely, on the upper line, notice that
$R$4:$U$27 is the range for
"Group 1" and (
$U$4:$U$27=$BA4) performs the match of whichever Traffic code appears in the SourceResult cells $BA4 to the Traffic codes in Group 1. All see that
(ROW($U$4:$U$27) - ROW($U$4)+1) is nothing more than a somewhat complicated way of generating a sequential array starting at 1, representing the row index for the first row in the Group 1 data table...so this array is simply {1;2;3;...;24}. I've shown this row indexing array formed using the same cell addresses where the Traffic codes are found for each group. This is an arbitrary choice and done only to ensure that the row indexing array corresponds directly to the Traffic code array. If all Group table data were the same length (let's say 20 rows long), then the somewhat complicated row indexing array expression could be replaced with a much simpler ROW(1:20), and there would be no need for added complexity.
On the lower line, COUNTIF($BA$3:$BA3,$BA4) counts the number of matches for the subject Traffic code (in $BA4) that have already been reported back and listed in the results table. The formula component in orange font is the cumulative sum in previously examined Groups for the same Traffic code (so those are already reported in the results table above the formula's current row position). We then add 1 in an attempt to return the next match (which might not exist and ultimately give an error...which is then handled by the IFERROR wrapper). Finally COLUMNS($BC:BC) provides the column index needed by the initial INDEX to return either column index 1,2,3, or 4 as the formula is pulled across the results table.
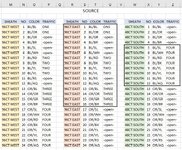
Here are the helper tables:
A small portion of the SourceResults table that merely copies over the original Source table:
...and the corresponding small portion of the Results table that incorporates lookups in the helper table. This version would be easier to edit/maintain as each of the "group" sections of the formula are very similar.